Serverless Concurrency Controlling
AWS Lambda has an impressive scalability, allowing it to quickly skyrocket up to tens of thousands instancess in seconds doc. This can lead to problems when integrated with services that scale with slower rates, forcing them to deal with unpredictable load spikes.
Scenario
Service to process events and store the results in the database.
At first glance it could look as simple as an integration of event bridge with lambda for events processing and later storing the results in the dynamo.

Feels like a nice cost-effective solution:
- Processing events only when there are some.
- Paying for compute only when there’s a work to be done.
- Storing results to dynamo and also paying only for WCU/RCU that were consumed.
Problems
Everything may work nicely untill event flow start to be spiky and unpredictable. Say we got a bunch of events in really short period of time, event bus started delivering those to lambda, forcing it to spawn new instances (aws lambda process one event at a time). Processed data will be stored into the table as it goes and this works until we hit the first limit of WCU, and database start throttling the requests. This is where we start loosing the data as in naive scenario lambda will try few more attempts (JS SDK v3 has 3 attempts by default) and fail.
Data loss points:
- lambda hit the limit of concurrently running instances (account level quota)
- lambda failed to process the request (hard timeout or bugs)
- database failed to process the request (throttling)
Solution
Ingress data losses because of downstream service issues like lambda hitting the concurrency limit or event processing related failures can be solved by introducing retry configuration and DLQ (dead-letter queue) for event bus rule. So that unprocessed events will be stored in dedicated queue wating for the review or bug fix with following redrive.
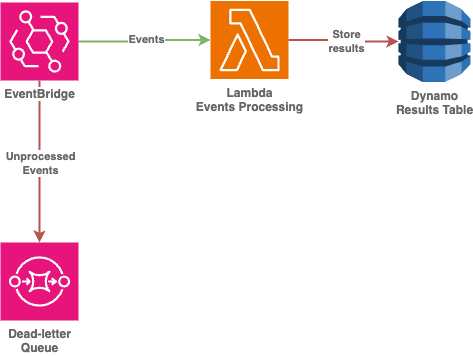
While current approach helps dealing with processing issues during ingress stage, it still allow already processes data to be lost due to database related issues. As we want to avoid porcessing the same ingress data after each rejection from downstream service, processing lambda places the result into the queue again (leveraging Storage-First design pattern) with own DLQ to guarantee that nothing was lost down the road.
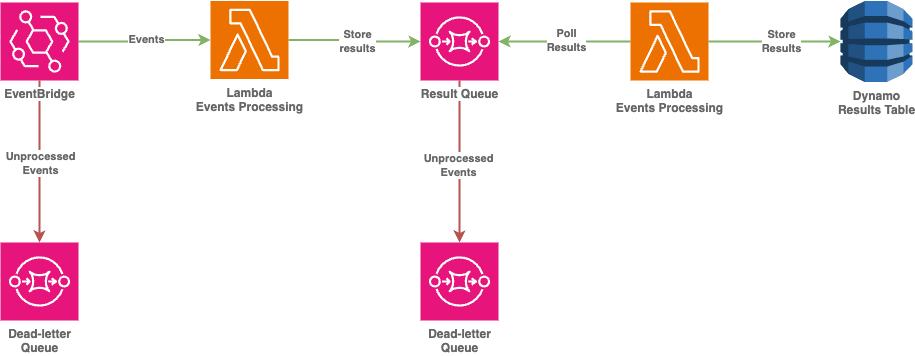
This time there’s a dedicated lambda only for handling the data persistence and it’s issues. Current approach uses active polling of the queue to adjust itself to database possibilities, data will be stored eventually, all spikes will get flattened in the queue.
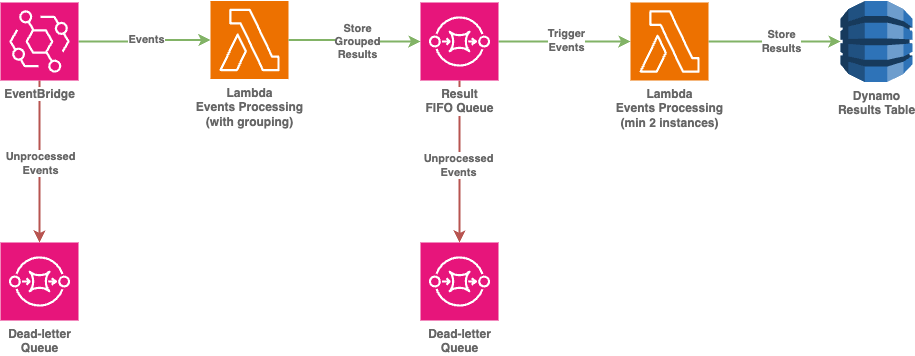
Alternative approach is to use SQS to pass the data to lambda. This one allows to define the boundaries for lambda concurrency in a more elegant manner than setting lambda reserverd concurrency limits (as it just throttles the lambda instances with all the consequences after that), but requires SQS FIFO with small redesign to introduce additional message grouping after processing phase. This will allow processing the data simultaneously by multiple lambda instances (number of instances denepnds on the number of separate message groups) and the concurrency level is directly controlled via event source mapping configuration.
Summary
That’s how initially simple design can get compilcated really fast whilt solving the problems. Active polling and reactive triggering by SQS together with storage-first gives a good level of reliability in data processing while requiers to pick one visely.